We are releasing Steerling-8B, the first interpretable model that can trace any token it generates to its input context, concepts a human can understand, and its training data. Trained on 1.35 trillion tokens, the model achieves downstream performance within range of models trained on 2–7× more data. Steerling-8B unlocks several capabilities which include suppressing or amplifying specific concepts at inference time without retraining, training data provenance for any generated chunk, and inference-time alignment via concept control, replacing thousands of safety training examples with explicit concept-level steering.
Steerling-8B: The First Inherently Interpretable Language Model

Author: Guide Labs Team
Published: February 23, 2026
Overview
For the first time, a language model, at the 8-billion-parameter scale, can explain every token it produces in three key ways. More specifically, for any group of output tokens that Steerling generates, we can trace these tokens to:
- [Input context] the prompt tokens,
- [Concepts] human-understandable topics in the model’s representations, and
- [Training data] the training data drove the output.
Artifacts
We are releasing the weights of a base model trained on 1.35T tokens as well as companion code to interact and play with the model.
Steerling-8B in Action
Below we show Steerling-8B generating text from a prompt across various categories. You can select an example, then click on any highlighted chunk of the output. The panel below will update to show:
- Input Feature attribution: which tokens in the input prompt strongly influenced that chunk.
- Concept attribution: the ranked list of concepts, both tone (e.g. analytical, clinical) and content (e.g. Genetic alteration methodologies), that the model routed through to produce that chunk.
- Training data attribution: how the concepts in that chunk distribute across training sources (ArXiv, Wikipedia, FLAN, etc.), showing where in the training data the model’s knowledge originates.
Loading explorer…
Overview
Steerling is built on a causal discrete diffusion model backbone, which lets us steer generation across multi-token tokens rather than only at the next-token. The key design choice is decomposing the model’s embeddings into three explicit pathways: ~33K supervised “known” concepts, ~100K “discovered” concepts the model learns on its own, and a residual that captures whatever remains.
We then constrain the model with training loss functions that ensure the model routes signal through concepts without a fundamental tradeoff with performance. The concepts feed into logits through a linear path, every prediction decomposes exactly into per-concept contributions, and we can edit those contributions at inference time without retraining. For the full architecture, training objectives, and scaling analysis, see Scaling Interpretable Models to 8B.

Performance
Despite being trained on significantly fewer compute than comparable models, Steerling-8B achieves competitive performance across standard benchmarks. The figure below shows average performance (across 7 benchmarks) versus approximate training FLOPs on a log scale, with vertical lines marking multiples of Steerling’s compute budget.
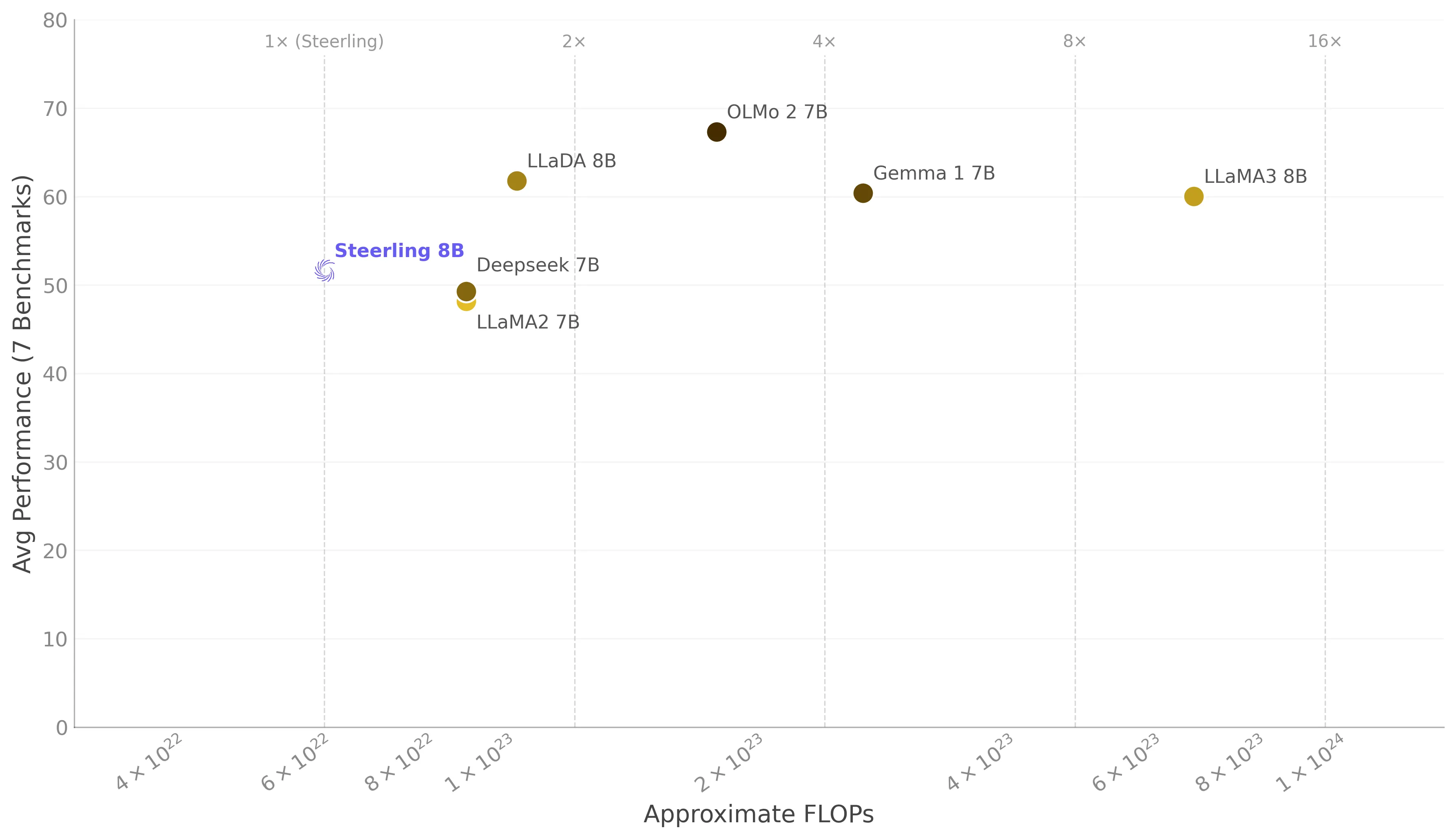
Steerling outperforms both LLaMA2-7B and Deepseek-7B on overall average despite using fewer FLOPs, and remains within range of models trained with 2–10× more compute.

Steerling performance across various benchmarks ranging from general purpose question answering to those focused on reasoning and math.
Interpretability
In the previous update, we shared several ways that assess how interpretable a model’s representations are. Here we provide another metric that gives insight into the model’s use of its concepts. On a held-out validation set, over 84% of token-level contribution comes from the concept module: the model is not just using the residual to make its predictions. This matters for control: if the model’s predictions genuinely flow through concepts, then editing those concepts at inference time actually changes what the model does rather than nudging a side channel while the real work happens elsewhere.

Token level logit distribution of Steerling-8B’s activations on a held-out validation set. Over 84% of token-level contribution comes from the concept module.
A useful check is what happens when we remove the residual pathway. On several LM Harness tasks, dropping the residual has only a small effect, which suggests the model’s predictive signal is largely routed through concepts rather than hidden “everything-else” channels.

Change in model performance across a variety of benchmarks with and without the model’s residual portion. This indicates that the model mostly relies on concepts, both supervised or discovered, for its outputs.
Finally, Steerling can detect known concepts in text with 96.2% AUC on a held-out validation dataset.
What this unlocks
In the coming weeks, we’ll be releasing deep dives on each of these capabilities:
- Concept steering: precise control via intervention;
- Concept discovery: what did Steerling learn that we didn’t teach it? We’ll open up the discovered concept space and show structure that surprised us.
- Alignment without fine-tuning: replace thousands of safety training examples with a handful of concept-level interventions.
- Memorization & training data valuation: trace any generation back to the training data that produced it, and assign value to individual data sources.
- The case for inherent interpretability: what do you gain when interpretability is designed in from the start, and what do you miss when it’s bolted on after the fact?
We’ll cover each of these in detail in upcoming posts, with quantitative evaluations and deployment-oriented case studies.